
1.SLMと特化モデル
SLMとは
SLMはSmall Language Modelの略称で、LLMの中でもパラメータサイズが少ないモデルのことを指します。NTTが開発したLLM「tsuzumi(※1)」もSLMの一種となります。SLMはLLMに比べて推論コストが低く、ローカル環境(※2)で運用することが容易です。そのため機密データを扱うような環境やオフライン環境でも導入しやすく、例えば機密データでは金融・保険分野や警察・国防といった安全保障分野への適用、オフライン環境としては船舶での運用などが期待されています。また、SLMは学習にかかるコストが低く、用途に合わせたカスタマイズ性に優れているという特徴があります。
特化モデルとは
LLMはあらかじめ汎用的なデータで事前学習されているため、業界特有の知識が必要なタスクに対しては適切な回答を生成できません。これに対し、LLMに業界特有の知識・用語を追加で学習させ、適切な回答を生成できるように調整したモデルのことを特化モデルといいます。
特化モデルは、以下の二つのファインチューニング手法を組み合わせて構築します。
- 継続事前学習:
事前学習済みの言語モデルに対して業界特有のデータを学習させることで、モデルに専門知識や語彙を獲得させる学習手法 - タスク特化学習:
モデルの出力や特定タスクの応答の形式を学習させるために実施する学習手法。Instruction-Tuningとも呼ばれる
現在、SLMを用いた特化モデル構築のニーズが高まっています。特化モデルに学習させる業界知識に顧客情報や社内情報が含まれる場合は、セキュリティやプライバシー保護の観点からローカル環境での運用が求められるためです。また、特化モデルの業務適用していく上では実際に運用しながら改善を繰り返していく必要があるため、カスタマイズ性の観点でもSLMが求められています。
特化モデルの現状と課題
現在、特定のドメインに対して特化モデルを構築した市中の事例はいくつかあるものの、それらはベンチマークによる評価で知識の獲得を確認しているものがほとんどです。ベンチマークは、資格試験の問題を解くように獲得した知識そのものを問うものが多く、お客さまが想定している実業務の中でのユースケースとは乖離があります。実業務での適用を見据えた特化モデルを構築するためには、お客さまの実際のユースケースに沿った実験と評価が不可欠ですが、そのような公開事例はまだ少ないのが現状です。NTT DATAではお客さまと連携し、実データおよび実業務を想定した評価・検証に取り組んでいます。本記事ではその一例として、保険業界での実施例を紹介します。
本記事では、限られたユーザーにのみ開放された領域という意味でローカルという呼称を用いています。オンプレミス環境に限らず、クラウド上に作られたクローズドな環境を含みます。
2.今回の検証事例
検証の概要
今回紹介する事例では、お客さまが扱う保険ドメインの知識を獲得したtsuzumiの構築に挑戦しました。
検証では、RAGシステムとの組み合せを想定した参照文書を照会し質問へ応答するタスク、営業職員と顧客間の会話・チャット履歴から営業情報を抽出するタスク、社内知識を含む質問へのQA回答タスク、の3つを対象としました。
特化モデル構築のアプローチとして、まず継続事前学習により業務・社内知識を獲得させ、「保険ドメイン特化モデル」を作成しました。その後タスク特化学習を行い、各タスクに特化した三つのモデルを構築しました。その後、各タスク特化モデルを対象に評価を実施しました。
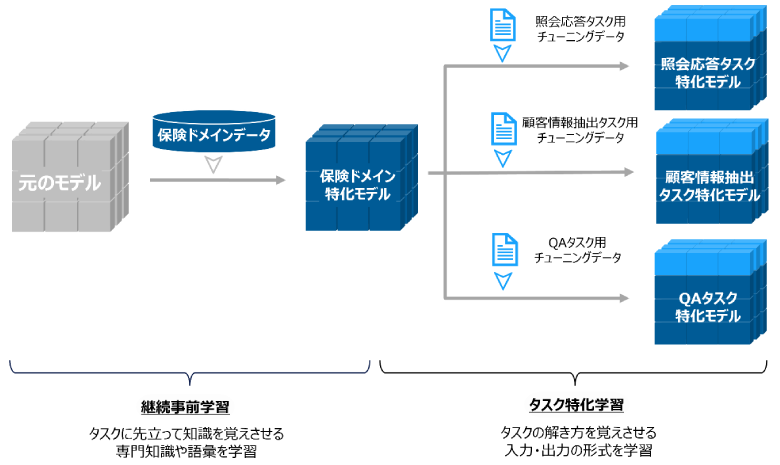
今回は継続事前学習の効果を見るためタスク特化学習のみを実施したモデルも作成し、比較対象としました。
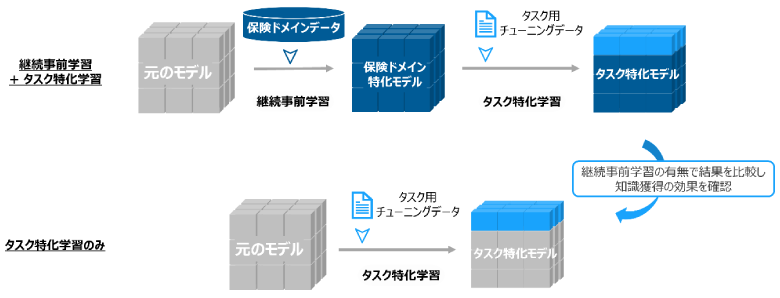
実験設定
Azure上にクローズドな環境を作成し、学習を実施してモデルを構築します。構築したモデルに対して推論を実行し評価を行います。
| 実行タスク | VMスペック | GPU | VRAMの容量 |
|---|---|---|---|
| 継続事前学習 | Standard_NC96ads_A100_v4 | A100 * 4 | 320 |
| タスク特化学習 | Standard_NC24ads_A100_v4 | A100 * 1 | 80 |
| 推論・評価 | Standard_NC16as_T4_v3 | T4 * 1 | 16 |
学習用に使用するデータセットの概要は以下の通りです。
| データセット | 件数 | ファイルサイズ | トークン数 | 概要 |
|---|---|---|---|---|
| 継続事前学習 | 68534 | 130MB | 34M | お客さま社内文書からテキスト抽出し、LLMを利用してデータ拡張を実施したデータ |
| 汎用的なQAタスクデータ | 1000 | 2MB | 230K | QAタスク特化学習用独自データセット |
| 参照情報と質問、回答のセット | 924 | 4.3MB | 440K | 回答生成タスク用。お客さま社内データから作成 |
| チャット履歴と定型質問、抽出結果jsonのセット | 1125 | 5.5MB | 570K | 営業情報抽出タスク用。お客さま社内データから作成 |
継続事前学習用の学習・評価データは、お客さまドメインのデータをベースとし、さまざまな言い換え表現を作成してデータ拡張を行っています。また、タスク特化学習用の学習・評価データは、お客さまにタスクに合わせた想定入出力を作成してもらいました。
評価結果
評価の結果、構築したタスク特化モデルは高い性能を発揮することが分かりました。一方、継続事前学習による知識獲得の効果は限定的で、合計約20M tokenの小規模データでは十分な精度向上が得られないことが分かりました。
照会応答タスク
RAGを想定した参照文書を照会し質問応答を行うタスクでは、RAGAS(※3)という評価手法を用いました。今回はその中でもモデルの回答が参照情報に忠実であるかどうかを表すFaithfulness、モデルの回答が正解(Ground Truth)とどの程度一致しているかを表すAnswer Correctnessの二つに着目しています。
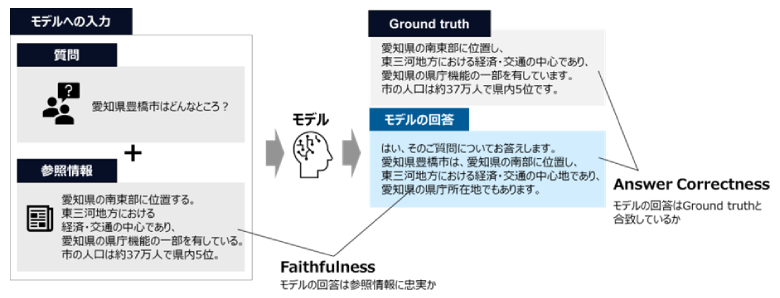
以下に、回答生成タスクの評価結果を示します。表中の±は標準誤差(※4)を示します。
| 指標 | ファインチューニングなし | タスク特化学習のみ | 継続事前学習 + タスク特化学習 |
|---|---|---|---|
| Faithfulness | 0.32 ± 0.033 | 0.79 ± 0.031 | 0.85 ± 0.025 |
| Answer Correctness | 0.32 ± 0.014 | 0.65 ± 0.020 | 0.63 ± 0.020 |
表のとおり、タスク特化学習によって大幅なスコアの向上が見られています。ただし、継続事前学習によるスコアの上昇幅は小さく、タスク特化学習が支配的な影響を与えたと考えられます。また、継続事前学習によって獲得した語彙がモデルの回答に含まれるケースも確認できました。よって、継続事前学習による知識の獲得は一部成功していると結論付けました。
営業情報抽出タスク
営業職員と顧客間の会話・チャット履歴からの営業情報抽出タスクでは、複数ある抽出項目それぞれについて正しく抽出できているかを集計し、正解率を求めています。
以下に、営業情報抽出タスクの評価結果を示します。
| 項目 | ファインチューニングなし | タスク特化学習のみ | 継続事前学習 + タスク特化学習 |
|---|---|---|---|
| 名前 | 0.54 | 0.99 | 0.98 |
| 職業 | 0.03 | 0.86 | 0.80 |
| 家族構成 | 0.06 | 0.57 | 0.51 |
| 趣味 | 0.04 | 0.59 | 0.84 |
| 保険加入状況 | 0.03 | 0.87 | 0.86 |
| 提案商品 | 0 | 0.84 | 0.84 |
| メールアドレス | 0.11 | 0.84 | 0.84 |
| 電話番号 | 0.08 | 0.99 | 0.99 |
| 面談日時 | 0 | 0.72 | 0.64 |
| 面談方法 | 0.17 | 0.87 | 0.97 |
| 訪問先 | 0.01 | 0.85 | 0.88 |
タスク特化学習のみでも正解率は大きく上昇していることが分かります。特に「面談日時」「面談方法」「訪問先」は顕著な精度向上が見られました。この結果から、お客さま独自の運用ルールや保険商品に関連する知識・語彙は獲得できていると考えられます。一方で、継続事前学習によるスコアの上昇幅は小さく、回答生成タスクと同様にタスク特化学習が支配的な影響を与えたと考えられます。
QAタスク
継続事前学習の効果については、QAタスクのスコアとperplexityを用いて評価を実施しました。QAスコアはLLMの出力が正解に対して正しいかどうかを人手で判定して集計したものです。perplexityは、モデルが次の単語を予測する際の不確実性の程度を測定する指標です。値が低いほど、あるドメインにおけるモデルの単語予測性能が高いことを示します。
以下に、QAタスクの評価結果を示します。
| 指標 | 学習前モデル | 継続事前学習 + タスク特化学習後モデル |
|---|---|---|
| QAスコア | 0 | 0.08 |
| perplexity | 10.5 | 6.4 |
継続事前学習によってperplexityが低下したことと、お客さまと私たちのチームによる定性的な評価結果を考慮し、継続事前学習による知識の獲得に一部成功していると結論付けました。一方で、ドメイン知識を問うQAタスクの精度は向上しませんでした。QAタスクの精度向上に寄与するようになるには、さらに大きなデータセットを用いた継続事前学習が必要と考えられます。
スコアの算出にはRAGASライブラリ(https://github.com/explodinggradients/ragas)のv0.1を使用
標準誤差は、テストデータから算出された平均スコアが真のスコアからどの程度の範囲でずれているかを示すものです。例えば、「85 ± 1.5」という表記は、85が平均スコアであり、その周りに1.5の誤差範囲があることを意味します。
3.まとめと今後の取り組み
今回はお客さまの持つ保険ドメインデータを用いて、継続事前学習とタスク特化学習により、tsuzumiをベースとする特化モデルを構築しました。タスク特化学習では、照会応答タスク、営業情報抽出タスクの二点で高い性能を発揮しました。この結果から、入力された情報をもとに質問に答えるタスクや、非構造化データから構造化データを抽出するタスク全般でも高い性能が期待されます。tsuzumiのようなSLMをファインチューニングすることで実現可能だと考えられるタスクについて、以下に具体例を示します。
| タスク種類 | タスク例 | 説明 | データセット |
|---|---|---|---|
| 照会応答 | RAG回答生成 | RAGシステムの回答生成部分を担当するタスク | 問い合わせに対する検索結果、回答例 |
| 対話エージェント | 人と対話するエージェントとして、ユーザーの参考データを参照しつつ出力を生成するタスク | ユーザーに関する情報、会話と応答例 | |
| 営業資料生成 | 過去の営業資料/提案書を参照しつつ新しい資料を生成するタスク | 過去関連資料と新規に必要となる情報、新規資料 | |
| 名寄せ用キーワード抽出 | 複数のフォーマットで書かれた文書から決められた項目を抽出することにより、内容が一致するものを探しやすくする | 文書と抽出されたキーワード | |
| 情報抽出 | 情報収集補助 | ニュース記事や企業情報などの文章から投資判断などに有用な項目を抽出する | ニュース記事などの文書と抽出されたキーワード |
| パラメータ抽出 | Function Callingに必要なパラメータを文章から抽出する | 関数呼び出し前の文章、後段の関数で使用するパラメータ |
また、継続事前学習による知識獲得の効果は一部見られたものの、タスクの精度向上に寄与するには至りませんでした。これは学習用データの規模が約20M tokenと小規模であったことが要因と考えられます。知識獲得によるタスクの精度向上を達成するため、今後はより大規模なデータによる検証や、データ拡張手法の開発に取り組んでいきます。
NTTDATAでは今回得られた特化モデル構築のノウハウを活かし、他業種・他業務にタスク特化モデルを展開し、お客さまの特化モデル構築ニーズに応えていきます。

NTT版大規模言語モデル「tsuzumi」についてはこちら:
https://www.rd.ntt/research/LLM_tsuzumi.html
NTT版LLM tsuzumiと連携したLITRON®の新サービスを提供開始
~閉域環境でセキュアに低コストで生成AI利用範囲を拡大~についてはこちら:
https://www.nttdata.com/global/ja/news/release/2024/012600/
RAGASについてはこちら:
https://github.com/explodinggradients/ragas
生成AI(Generative AI)についてはこちら:
https://www.nttdata.com/jp/ja/services/generative-ai/
tsuzumiについてはこちら:
https://www.nttdata.com/jp/ja/lineup/tsuzumi/
あわせて読みたい: