
- 目次
1.従来のアプローチが抱える限界
現代の企業にとって、データは意思決定に不可欠な資産となっています。企業に導入されるデータプラットフォームは、ビジネスインテリジェンス(BI)向けのデータウェアハウス(DWH)から始まり、機械学習やAI対応のデータレイク(Data Lake)が加わるなど、顧客のニーズに応えるべく進化してきました。さらに、近年は生成AIの活用ニーズも高まり、データ分析プラットフォームに求める機能が一層高度化しています。
従来のデータプラットフォームは、パブリッククラウドサービスやModern Data Stackを構成するサービスを組み合わせる方式が主流でした。特にAWSでは、「ビルディングブロック」という考え方に基づき、300以上のサービスから要件に合うものを選び、柔軟にシステムを提供してきました。しかし、このアプローチは高い柔軟性を実現する一方で、サービスが寄せ集められているため、利用者にとっても運用者にとっても、必ずしも使いやすいとは限らないという課題を浮き彫りにしています。
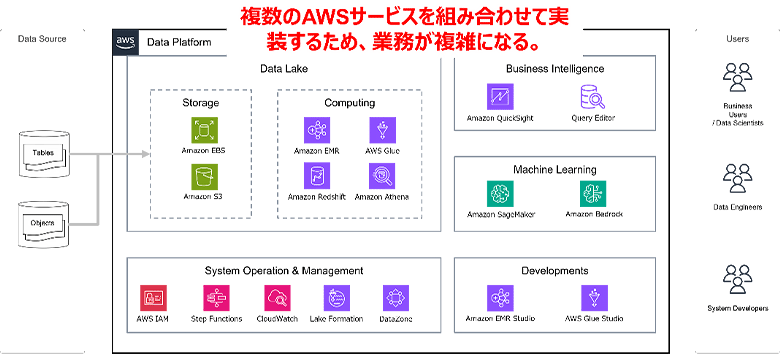
図1:データプラットフォームにおけるビルディングブロックによる課題
(1)データプラットフォームにおけるビルディングブロックの課題(利用者側)
データ収集
- 統括的なデータカタログ機能の欠落Amazon S3やAmazon Redshift、サードパーティーのデータベース(以下、DB)など、複数のデータソースが存在すると、目的のデータセットが探しづらくなります。また、データセットの名前から中身を推測するのも困難です。このようなデータのサイロ化やビジネスデータの欠如が、データ活用の障壁となっていました。 また、データ加工のプロセスにおいて、複数のデータストア、複数のデータ加工ツールを利用することがあり、一元的にデータのリネージ(上流、下流)を把握することも困難でした。この課題を解決するために、サードパーティーのカタログツールを導入することがよくありますが、高価なライセンス費用やツールの継続的なメンテナンスが必要です。
- 運用者への依頼が必要で、時間がかかるセキュリティやガバナンスなどの制約により、利用者がデータの追加やETLパイプラインの作成、作業スペースの準備、データソースへのアクセス権設定などを管理者に依頼しなければならない場面が多くありました。そのため、対応待ちが発生し、データ収集がスムーズに進みませんでした。
データ分析
- ツールがサービスごとに重複し、一貫性がないAmazon RedshiftとAmazon Athenaにはそれぞれ異なるクエリエディタがあり、AWS Glue、Amazon EMR、Amazon SageMakerにも別々のノートブックが存在するなど、ツールが重複していました。さらに、コードはサービス間で散在し、バージョン管理も統一されておらず、開発体験に一貫性が欠けていました。
- 複数のデータソースをまたぐデータ処理が難しいデータセットが複数のデータソースにサイロ化されている場合、データを横断的に扱うためにはデータの移動など事前準備が必要で、スムーズなデータ活用が難しい状況でした。
システム化
- 運用へ向けた作業の敷居が高いデータ活用は直接的な分析やモデル開発だけでなくパイプラインの構築や実行などさまざまなタスクを含みます。分析者がこれを行うには、開発者向けに作られたマネジメントコンソールから的確なサービスを選び使う必要がありました。これでは敷居は高く、場合によってはパイプラインの構築や実行は開発者の作業となるため、時間が掛かりました。
ビジネス利用
- 企画から実行までに時間がかかる上記の課題により、ビジネス活用が行われるまでには、多くの障壁をクリアする必要がありました。顧客が、データとAIを通じたビジネス変革という本来の目標に集中できるようにすることは常に容易ではありませんでした。
さらに、運用担当者にとっても、複数のサービスを組み合わせたシステムは複雑で、管理の負担が大きくなっていました。
(2)データプラットフォームにおけるビルディングブロックの課題(運用者側)
運用
- データ全体像の把握が難しいAmazon RedshiftやAWS Glueなど複数の場所にデータが保管されている場合、カタログもデータベースごとに分散しており、システム全体でどのデータが連携されているのかが把握しにくくなります。さらに、テーブル間の依存関係も追いづらい問題が発生していました。
- 定常業務が複雑化データの保管場所が複数に分かれている場合、データソースごとにアラート設定などを行う必要があります。また、システムの異常発生時には、影響範囲の特定が困難であり、場合によっては担当者の経験に頼らざるを得ない状況もありました。
- 利用者からの問い合わせや依頼対応が負担に各サービスへの権限付与や作業スペースの割り当ては運用担当者の作業が必要です。また、Amazon RedshiftやAWS Glueなど複数のデータソースに関する問い合わせ対応や、ユーザーがマネジメントコンソールの操作に不安がある場合、パイプラインの構築や実行も依頼されることが多く、運用担当者の負担が増大していました。
- 新しいサービスの導入に多大な労力がかかる新しいサービスを導入する際には、そのサービスの設計だけでなく、一貫したセキュリティやガバナンスを担保するために、既存サービスとの整合性を担保した設計が求められます。さらに、必要に応じてカスタマイズした監視の仕組みを追加するなど、複雑な運用設計を行うことも求められました。その結果、新しいサービスの提供までに時間が掛かり、データ活用の推進が滞る原因となっていました。
2.Amazon SageMaker Unified Studioの登場
そして今回、AWSからオールインワン・データプラットフォームを実現する新サービスAmazon SageMaker Unified Studioが登場しました。このサービスは、データレイクハウスアーキテクチャによりAWSの各サービス間のデータを統合し、データのサイロ化を防ぐことができます。また、統合されたUIから複数のサービスやデータソースを利用することができ、分析業務の生産性を高めることができます。ここでは、Amazon SageMaker Unified Studioの強力な機能と、一貫した開発体験の魅力に焦点を当ててご紹介します。
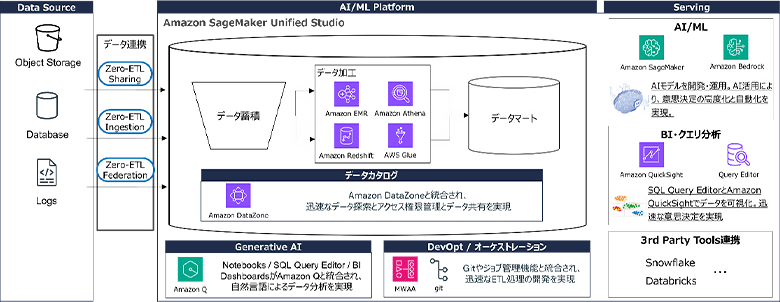
図2:AWSオールインワン・データプラットフォーム(Amazon SageMaker Unified Studio)のイメージ図
(1)パワフルな分析環境の提供
Amazon SageMaker Unified Studioでは、ドメイン単位でリソースを管理しており、AWSマネジメントコンソールからドメインを作成すると、専用のポータルURLが割り当てられ、作業スペースはプロジェクト単位で内部管理されます。アナリティクスやAI向けの複数サービスのほか、Amazon Managed Workflows for Apache Airflow(MWAA)などのワークフロー管理サービスが統合されており、分析担当者は多様なタスクをスムーズに実行できます。
- さまざまなアナリティクス向けサービスとの連携AWS GlueやAmazon Redshift、Amazon SageMaker、Amazon Bedrockなど、さまざまなサービスをAmazon SageMaker Unified Studio内で整理して提供します。データの処理や活用に最適なサービスを選択し、効率よく作業できます。
- 運用を含む包括的なサポートAIモデルの再訓練など、定められた手順に基づく業務の自動化が統合されており、分析担当者は運用担当者に依頼せずに迅速に実行できます。また、マネジメントコンソールと比較して、無関係なサービスを隠すことで、適切なサービスを選びやすい画面となっています。
- インフラの自動設定Amazon SageMaker Unified Studioはインフラ設定を自動化し、分析担当者はプロジェクトプロファイルを使用して迅速に作業を開始できます。これにより、運用担当者の業務もスムーズになります。
また、Amazon SageMaker Unified Studioは運用担当者の業務もスムーズにします。
- Zero-ETLによるデータソースとの連携複数のデータソースとの接続用コネクタが提供され、分析担当者は手間を減らしてデータを迅速に活用できます。
- データマネジメントの強化データリネージやデータ品質のモニタリング機能が提供され、運用担当者はデータの状態を管理しやすくなります。
(2)ユーザーに一貫性を持った開発体験を提供
Amazon SageMaker Unified Studioは、重複する機能を整理し、1つの統合されたサービスとして提供します。データはひとつの場所に集約され、情報はカタログとして提供されます。また、ノートブックなどのツールも、サービスを横断して使用できます。これにより、データサイエンティストやデータエンジニアに一貫性のある開発体験を提供します。
- 横断して使用できるツールAmazon SageMaker Unified Studioでは、単一UIから複数のサービスを利用することができます(例:AWS GlueとAmazon SageMakerのノートブック、Amazon RedshiftとAmazon Athenaのクエリエディタは共通のUIを使用)。
- 探しやすいカタログAmazon DataZoneと連携することで、統一したUIからシームレスにAmazon DataZoneの用語集やメタフォームを活用したカタログ検索機能が利用できるようになるため、組織内のデータの検索性が向上します。また、構造化データや非構造化データに対するアクセス制御も一貫して行えます。
- データの一元管理データがAmazon RedshiftやAWS Glueのどこにあっても、Iceberg APIを通じてデータとして読み書きが可能です。これにより、データの移動や複数のデータソースをまたぐクエリ処理がスムーズに行えるようになります。
(3)データプラットフォーム構築の効率化
これまでのAWS上でのデータプラットフォーム構築は、多くのサービスを組み合わせて要件に合うものを構築する必要がありました。利用するサービスを選定する際に、機能や非機能要件を満たすこと、または、複数のAWS サービスへの深い知識が求められ、調査には時間が掛かりました。サードパーティーの製品を組み込む場合にはさらに検討に時間が掛かりました。
Amazon SageMaker Unified Studioの登場により、サービスをビルディングブロック方式で構築するだけでなく、雛形に沿ったインフラの自動設定やデータコネクタを活用し、さまざまなシステムと連携するという選択肢が提供されます。また、データプラットフォームの開発と運用のオーバーヘッドを最小限にできるため、お客さまが、データとAIを通じたビジネス変革という本来の目標に集中できるようになります。
3.NTTデータの取り組み
NTTデータでは、豊富なノウハウを基に、AI・データの民主化を推進するクラウド型ビッグデータプラットフォーム「Trusted Data Foundation®(TDF)」を提供し、Amazon SageMaker Unified Studioを含めて幅広いサービスを展開しています。これまでもビルディングブロックに関する課題解決に向けて、Databricks のデータ・インテリジェンス・プラットフォームやMicrosoft Fabric といったオールインワン・データプラットフォームを活用し、データとAIを駆使したデジタルトランスフォーメーションの加速を支援してきました。
参考:
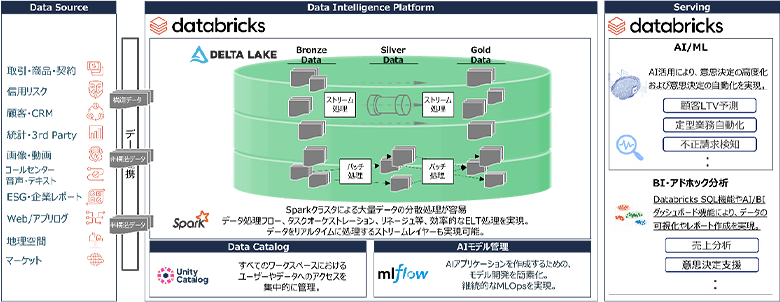
図3:データ・インテリジェンス・プラットフォーム(Databricks)のイメージ図
Amazon SageMaker Unified Studioも、このトレンドに沿うものです。AWSサービスをご利用中のお客さまにとって、Amazon SageMaker Unified Studioは親和性が高く、迅速にオールインワン・データプラットフォームを構築できるようになるため、新たな選択肢が増えることは非常に喜ばしいことです。
4.最後に
Amazon SageMaker Unified Studioの強力な機能や、統合による一貫した開発体験の価値を感じていただけたでしょうか。この記事を通じて、Amazon SageMaker Unified Studioにご興味を持っていただければ幸いです。また、AWSブログにて、Amazon SageMaker Unified Studioの機能を、画面キャプチャを交えながらさらに詳しく解説する記事を公開しています。こちらもぜひご覧ください。
NTTデータでは、300名以上の経験豊富なコンサルタントやデータサイエンティストが、データ分析やデータマネジメント、データ活用促進のためのトレーニングや啓発活動を通じて、お客さまのビジネスの加速を支援いたします。次期データプラットフォームの導入を検討中の経営者やIT担当者の皆様、ぜひお気軽にご相談ください。

NTTデータによるAmazon SageMaker Unified Studioの機械学習モデル開発の機能検証についてはこちら
https://aws.amazon.com/jp/blogs/psa/sagemaker-unified-studio-ml-model-development-basic-investigation-by-nttdata/
Trusted Data Foundation®についてはこちら
https://www.nttdata.com/jp/ja/lineup/tdf/
AI・データの民主化を促進するデータ分析基盤の提供を開始についてはこちら
https://www.nttdata.com/global/ja/news/release/2019/032500/
AWSとクラウドを活用したデジタルビジネス推進に関する戦略的協業を開始についてはこちら
https://www.nttdata.com/global/ja/news/release/2021/121600/
NTTデータ データブリックスパートナーサイトについてはこちら
https://www.nttdata.com/jp/ja/lineup/databricks/
統合データ分析基盤を提供するデータブリックスのパートナー評価で日本企業初の「Elite」を獲得についてはこちら
https://www.nttdata.com/global/ja/news/topics/2024/052300/
あわせて読みたい: